
斗鱼直播数据分析(一)之利用python3爬虫获取数据
前言
随着2012年开始直播行业的兴起,吃外卖看直播成了很多大学生每天都会做的事(当年我们宿舍的就是这么过来的,伴随着最近自己很喜欢的一位主播跳槽到海鲜台,所以就打算扒一扒这个海鲜台,本篇文章分成2个部分:
利用python3爬虫获取数据
爬虫数据分析及可视化
本篇先对第一部分进行阐述。
一、网站爬取逻辑分析
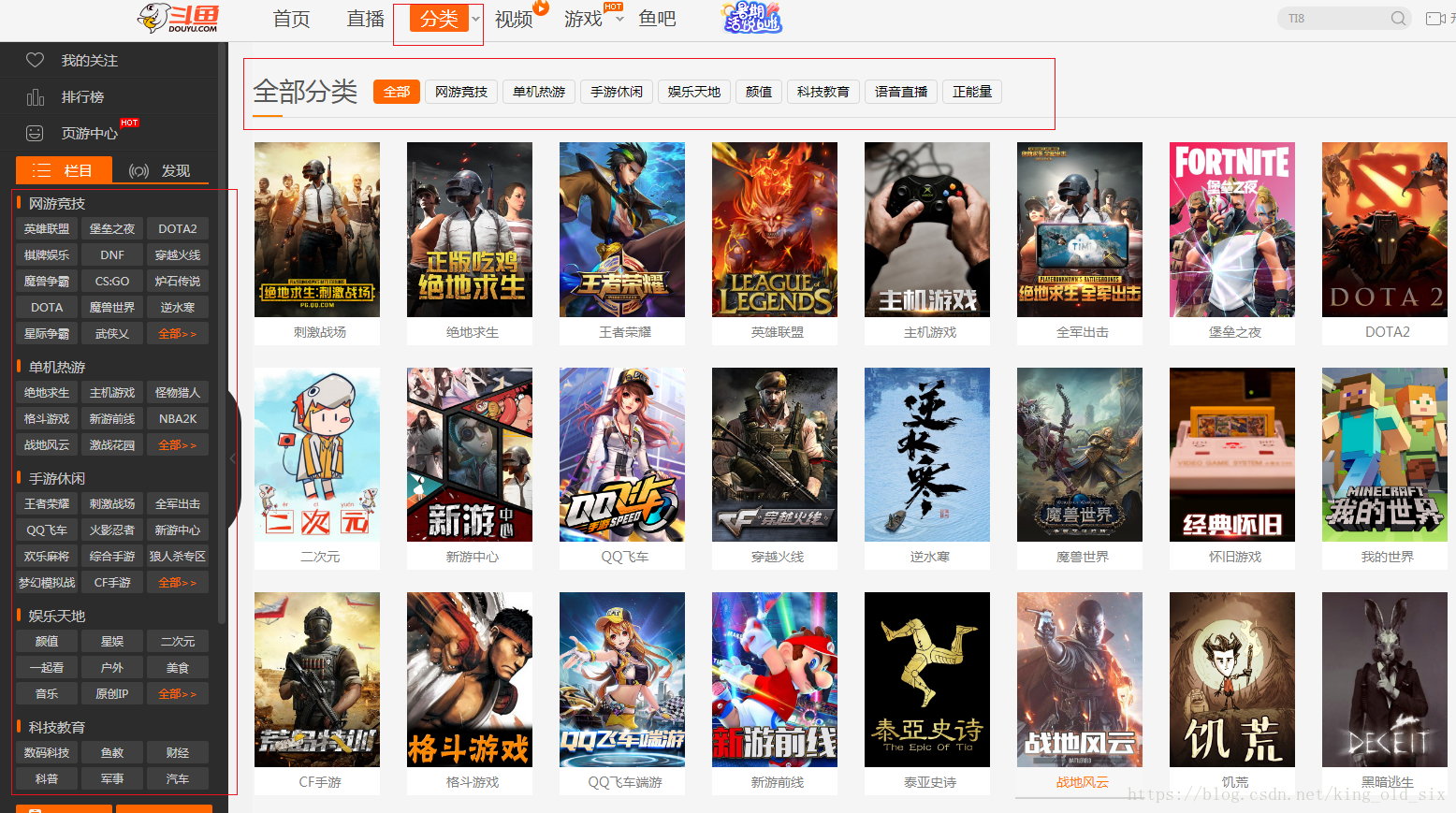
基于上图,我们可以看出:
将分类做为入口,获取每个分类下的游戏列表,爬取分类下每个游戏的url,然后进入具体的游戏页面,拿英雄联盟为例:
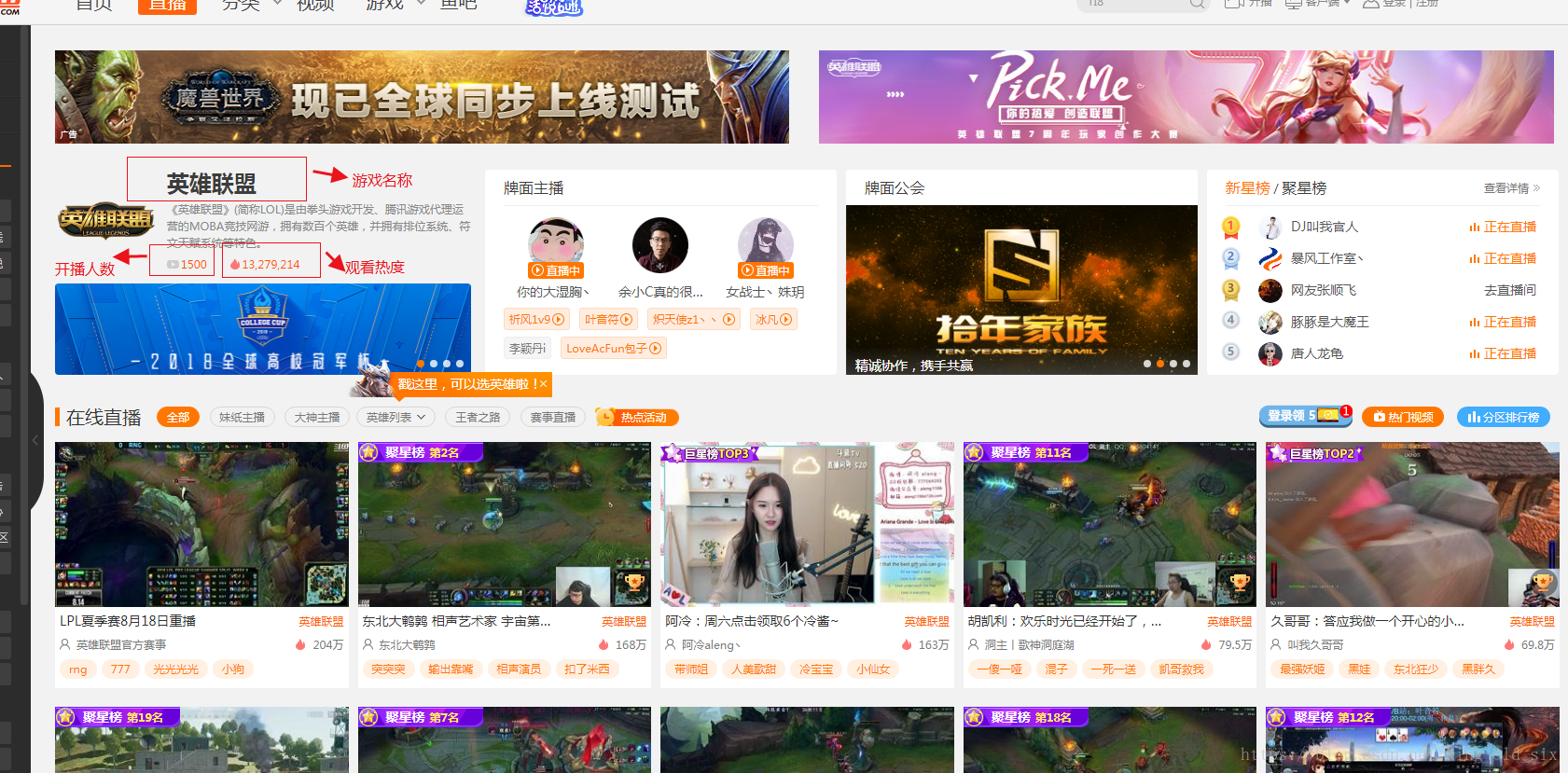
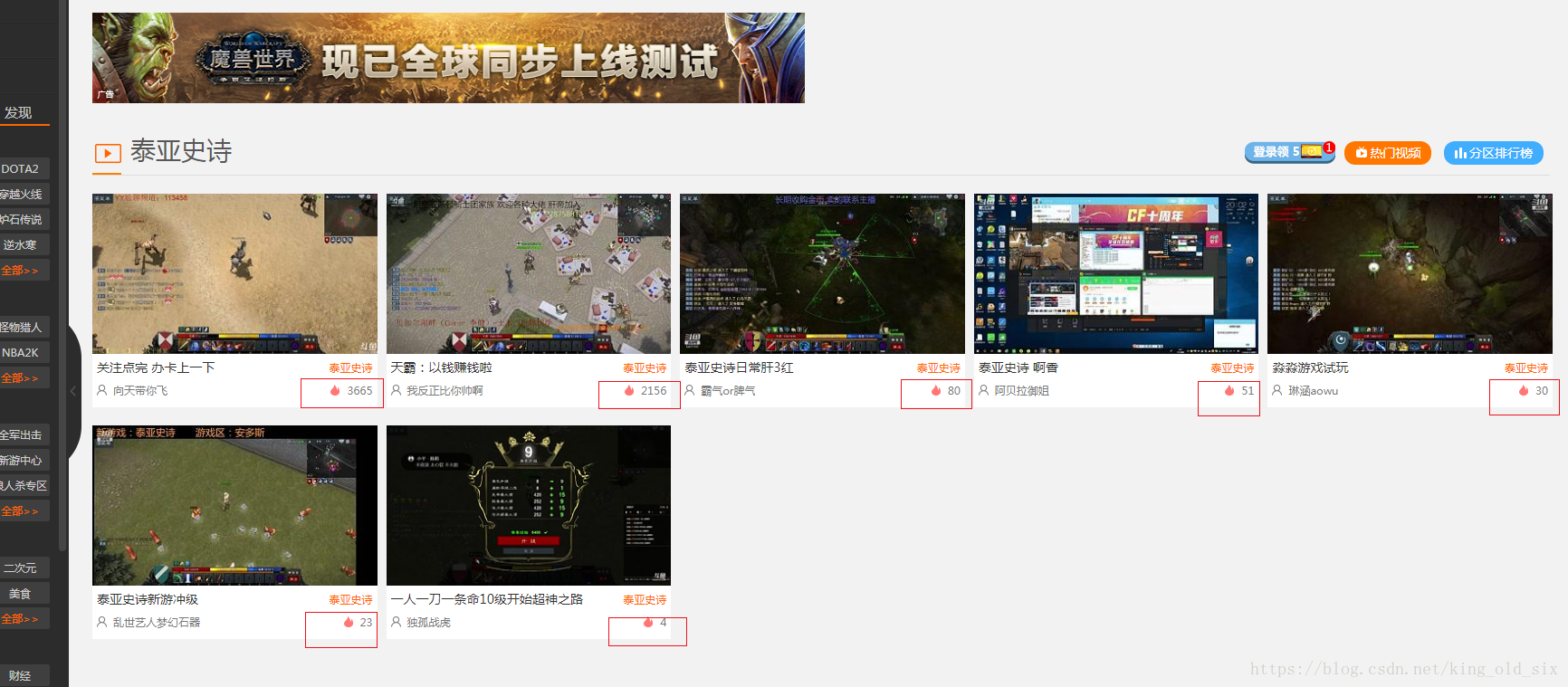
基于上图,我们在页面可以轻易的获取到以下三个信息:
游戏名称:、开播人数:、观看热度:
海鲜台已经帮我们做好统计,我们直接截取就ok了。
但是,万一有些直播节目斗鱼没有做这方面的统计呢?比如下面这个游戏直播页面是这样的:
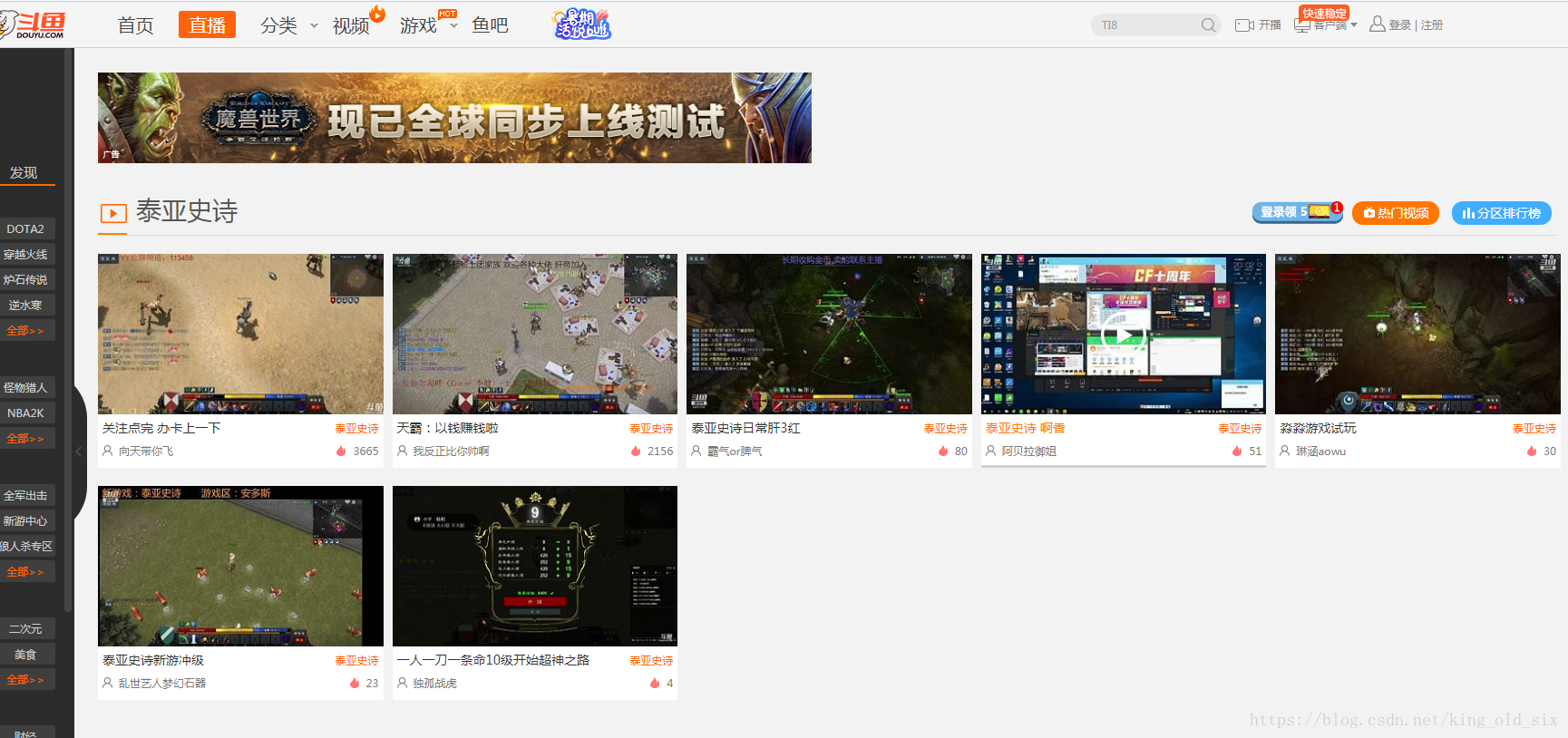
从上图可以发现,我们只能获取到游戏名称:,拿不到开播人数:和观看热度:。
对于这样的情况,我们能想到的就是自己做统计,或许搜索框是我们的一个入手点:
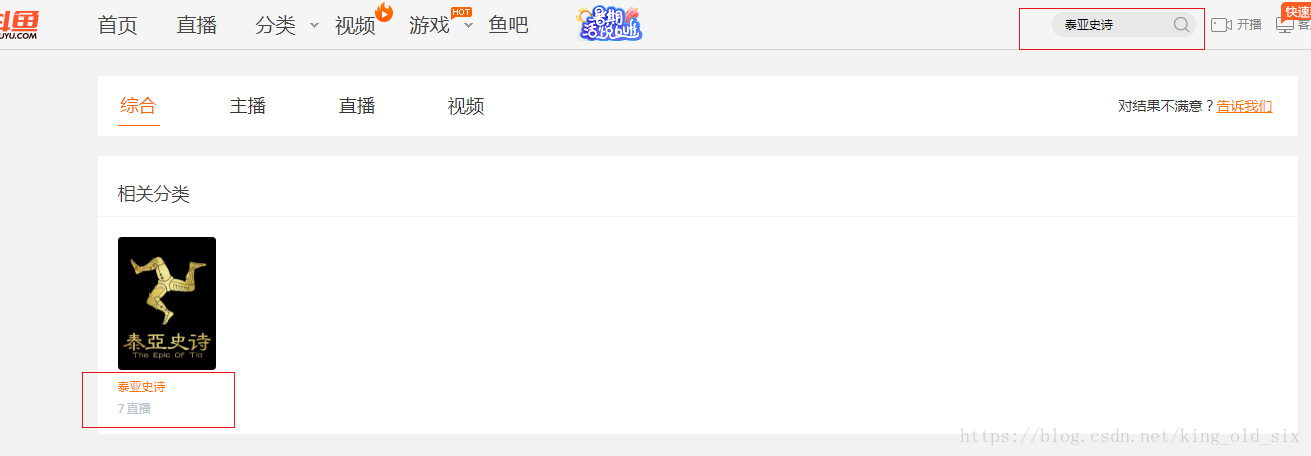
果然,通过搜索框,我们能获取到开播人数,通过搜索接口查询相比我们进去游戏直播列表一个一个页面做统计是不是便捷了很多,有了开播人数,观看热度的获取也挺容易:
将每一个直播的热度做一个统计就能得到。
二、爬虫步骤实现
1.获取每个分类的URL
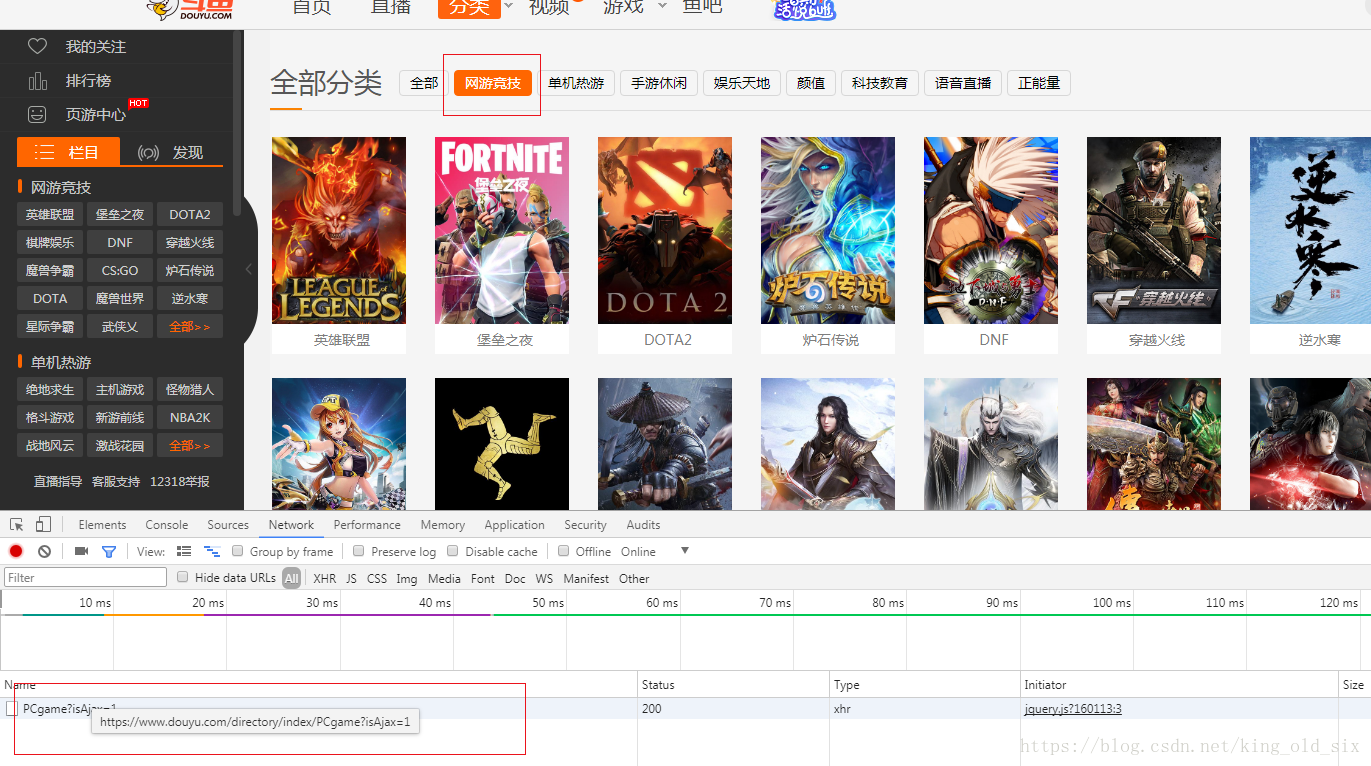
点击顶部的,我们能从浏览器的network中获取到如下url:,这就是我们需要的分类url,其他分类也可以通过这样的做法来查看获取,获取到全部分类的url之后,我们可以定义一个字典来存放我们的分类:
之利用python3爬虫获取数据")
之利用python3爬虫获取数据")
版权声明
本文仅代表作者观点,不代表xx立场。
本文系作者授权xx发表,未经许可,不得转载。
相关文章





推荐
-
 中甲比赛积分排名表(中甲积分最新排名榜) 10个月前 (01-28)
中甲比赛积分排名表(中甲积分最新排名榜) 10个月前 (01-28) -
 中山夫妻机选擒获双色球182万元 10个月前 (01-28)
中山夫妻机选擒获双色球182万元 10个月前 (01-28) -
 亚洲杯C 组末轮前瞻:伊朗VS阿联酋,中国香港VS巴勒斯坦 10个月前 (01-28)
亚洲杯C 组末轮前瞻:伊朗VS阿联酋,中国香港VS巴勒斯坦 10个月前 (01-28) -
 受一球球半是什么意思 球半和一球球半的区别 10个月前 (01-28)
受一球球半是什么意思 球半和一球球半的区别 10个月前 (01-28) -
 2021s赛小组赛积分,2020s赛积分规则 10个月前 (01-28)
2021s赛小组赛积分,2020s赛积分规则 10个月前 (01-28)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。